
يزعم نظام الذاكرة المُعتمِد على الذكاء الاصطناعي MemPalace، الذي تشارك في تطويره ميلا جوفوفيتش، أنه حقق نتائج اختبار كاملة فاشتُهر بسرعة، لكن تم فضحه من قبل المجتمع على أنه ينطوي على غش في الاختبارات وتضليل في البيانات. تكشف الاختبارات الفعلية عن تضخيم في النتائج ووجود عدد كبير من الأخطاء؛ وقد اعترف الفريق بوجود عيوب وبدأ في العمل على إصلاحها.
ميلا جوفوفيتش تُنشئ «قصر ذاكرة» للذكاء الاصطناعي، ما يثير اهتمامًا من الخارج
أمس (4/7)، كان في أوساط الذكاء الاصطناعي خبرٌ كبير يتمثل في أن النجمة الهوليوودية ميلا جوفوفيتش (Milla Jovovich)، المعروفة بأفلام مثل《Resident Evil (المقيم الشرير)》و《The Fifth Element (العنصر الخامس)》، جنبًا إلى جنب مع المطور Ben Sigman، استخدمت Claude Code للمساعدة في تطوير نظام «MemPalace» مفتوح المصدر للذاكرة المعتمدة على الذكاء الاصطناعي.
في غضون لحظات، انتشرت على نطاق واسع مقولة «نجمة هوليوودية عملاقة تعبر إلى مجال جديد وتقدّم مشروعًا بدرجة كاملة»، وحصل MemPalace حتى الآن على أكثر من 20 ألف نجمة على GitHub، لكن سرعان ما أثار ذلك شكوك مجتمع المطورين: هل الأمر فعلاً ذو محتوى أم مجرد دعاية؟
لنبدأ بالحديث عن دوافع ظهور MemPalace؛ إذ تذكر الوثائق الرسمية أن الهدف هو معالجة مشكلة مفادها أن محتوى المحادثات بين مستخدمي أنظمة الذكاء الاصطناعي وبين قراراتها، ومناقشات بنية النظام، غالبًا ما تختفي بعد انتهاء جلسة العمل، ما يؤدي إلى «انخفاض إلى الصفر» لجهود شهور.
ولتجاوز هذه المشكلة، يعتمد MemPalace بنية مكانية لتخزين الذاكرة، حيث يتم تصنيف المعلومات بوضوح إلى مناطق الجناح التابعة للأفراد أو المشاريع، بالإضافة إلى هياكل مختلفة المستويات مثل الممرات والغرف والدرج، مع الاحتفاظ بالنص الأصلي للمحادثات لتُمكّن من الاستعلام الدلالي لاحقًا.
يُصرّح فريق التطوير بأن MemPalace حقق 100% في معيار تقييم الذاكرة طويلة الأمد LongMemEval، كما بلغ 96.6% من الدقة دون استدعاء أي واجهة برمجة تطبيقات خارجية. علاوة على ذلك، يمكن تشغيله بالكامل محليًا دون الحاجة إلى الاشتراك في خدمات سحابية، ويحتوي على نظام لهجة AAAK يُزعم أنه يحقق ضغطًا بلا فقدان بمعدل 30 مرة.
مصدر الصورة: GitHub ميلا جوفوفيتش، نجمة أفلام أمريكية، تُنشئ «قصر ذاكرة» للذكاء الاصطناعي، ما يجذب اهتمامًا من الخارج
معاونو الصناعة والمجتمع يتشككون معًا: اختبارات وأساليب تسويق فيها عيوب
لكن إنجاز MemPalace المزعوم في LongMemEval بدرجة كاملة لم يمض وقت طويل حتى أثار شكوكًا من المنافسين.
أشار PenfieldLabs، وهو أيضًا جهة تقوم بتطوير أنظمة ذاكرة للذكاء الاصطناعي، إلى أن ادعاء MemPalace بتحقيق درجة كاملة في مجموعة بيانات LoCoMo أمر غير ممكن رياضيًا، لأن الإجابات القياسية في مجموعة البيانات نفسها تتضمن أصلًا 99 خطأً.
حلل PenfieldLabs ووجد أن نتيجة MemPalace البالغة 100% تنشأ عن ضبط عدد عمليات الاسترجاع على 50 مرة، بينما لا تتجاوز أعلى مستويات عدد مراحل المحادثة في مجموعة الاختبار 32 مرة، ما يعني أن النظام يتجاوز مرحلة الاسترجاع مباشرة ويُسلم جميع البيانات لنموذج الذكاء الاصطناعي لقراءتها.
وبالنسبة لنتيجة 100% في LongMemEval، تم اكتشاف أن فريق التطوير ركّز على 3 مشكلات محددة تم فيها ارتكاب خطأ أثناء التطوير، وكتب كود إصلاح مخصص لها، ما يثير شبهة التحيّز في الغش على مجموعة الاختبار.

مصدر الصورة: Reddit أشار PenfieldLabs من منافسين الصناعة إلى أن ادعاء MemPalace بتحقيق درجة كاملة في مجموعة بيانات LoCoMo أمر غير ممكن رياضيًا
اختبار فعلي من مستخدمي GitHub: تتضمن الاختبارات الأساسية عناصر تضليل
علق hugooconnor، وهو مستخدم على GitHub، بعد إجراء اختبار فعلي، بأن MemPalace يزعم بلوغ دقة الاسترجاع حتى 96.6%، لكن في الواقع لم يستخدم إطلاقًا بنية «قصر الذاكرة» التي يروج لها MemPalace. يقول hugooconnor إن اختباراتهم كانت مجرد استدعاء الإمكانيات الافتراضية لقاعدة البيانات السفلية ChromaDB، دون أي اشتراك في منطق التصنيف الذي تشدد عليه مناطق الجناح أو الغرف أو الأدراج الخاصة بالمشروع.
بعد اختبارهم، اكتشف hugooconnor أنه عندما يتم تفعيل منطق التصنيف الخاص بهذه «قصور الذاكرة» فعليًا، تنخفض نتائج الاسترجاع بدلًا من أن ترتفع. على سبيل المثال، في وضع الغرف تنخفض الدقة إلى 89.4%، وبعد تفعيل تقنية ضغط AAAK تنخفض الدقة أكثر إلى 84.2%، وكلاهما أقل من أداء قاعدة البيانات الافتراضي.
كما انتقد hugooconnor أسلوب الاختبار: إذ يتعمد بيئة الاختبار في MemPalace تضييق نطاق الاسترجاع لكل سؤال إلى حوالي 50 مرحلة محادثة، ما يجعل البحث عن الإجابة في مكتبة عينات صغيرة جدًا أمرًا سهلًا للغاية.
وعند توسيع النطاق إلى أكثر من 19,000 مرحلة محادثة في سياق واقعي، تنخفض دقة البحث بالكلمات المفتاحية التقليدية إلى 30% فقط، ما يشير إلى أن أسلوب اختبار MemPalace الحالي يُخفي مشكلة البحث الفعلية الصعبة.
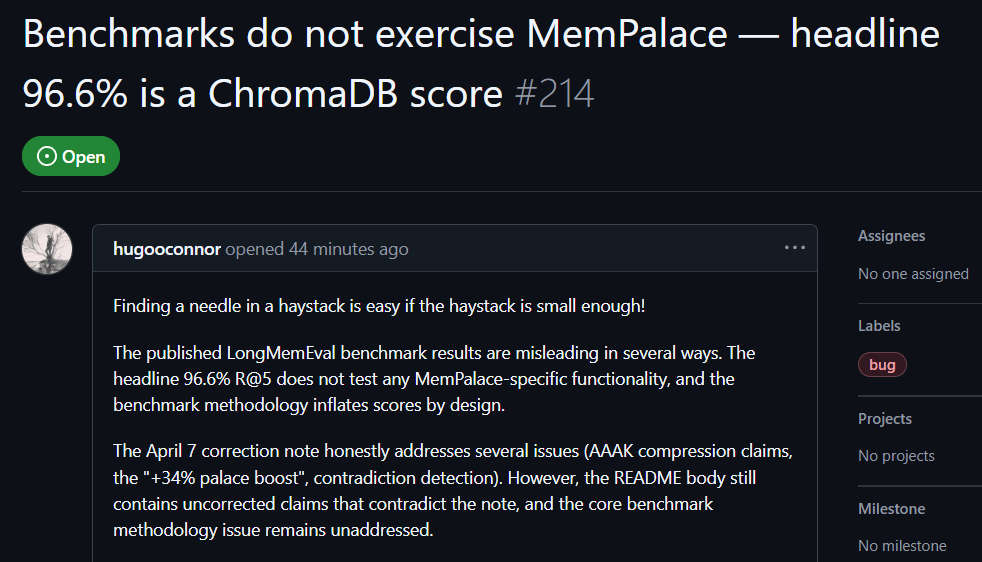
مصدر الصورة: GitHub اختبار فعلي من مستخدمي GitHub: يتضمن اختبار MemPalace الأساسي عناصر تضليل
وفي الوقت نفسه، رغم أن فريق التطوير نشر بيان تصحيح واعترف بأن تقنية AAAK قد تم التحقق منها على أنها ضغط مع فقدان، وتعهد بتعديل وثائق التوصيف وتصميم النظام وفقًا لانتقادات المجتمع الشديدة. لكن وثيقة الوصف الرئيسية للمشروع لا تزال تحتفظ بعدة ادعاءات مبالغ فيها غير مصححة، بما في ذلك الادعاء بـ «ضغط بلا فقدان 30 مرة» و«تحسين في الاسترجاع بنسبة 34%»، كما أن مخططات المقارنة مع المنافسين الآخرين تفتقر بالكامل إلى مصادر ومراجع.
مواجهة كود MemPalace الأصلي لمجموعة من الأخطاء Bug
مع تنزيل المزيد والمزيد من المطورين للاختبارات، ظهرت على منصة GitHub كمية كبيرة من تقارير الأخطاء المتعلقة بالكود الأصلي لـ MemPalace.
قامت cktang88 بإدراج عدة عيوب جسيمة، بما في ذلك عدم عمل أوامر الضغط والتسبب في انهيار النظام، وأخطاء في منطق حساب عدد الكلمات في الملخص، وعدم دقة البيانات الإحصائية لحفر الغرف، فضلًا عن أن الخادم يقوم عند كل استدعاء بتحميل جميع بيانات التفسير إلى الذاكرة، ما يؤدي إلى مشكلة استهلاك موارد شديد.
ومن بين المشكلات الأخرى المذكورة أيضًا أن النظام يكتب أسماء أفراد عائلة المطورين بشكل إجباري في ملف الإعدادات الافتراضي، وأنه يوجد حد عرض إجباري عند الاستعلام عن الحالة لبيانات تصل إلى 10k سجل.
وبخصوص هذه المشكلات، بدأ مجتمع البرمجيات مفتوحة المصدر بالفعل في إصلاحها بشكل نشط. قدّم المستخدم adv3nt3 عدة طلباتلإصلاح الأخطاء، بما في ذلك تصحيح البيانات الإحصائية للحفر، وإزالة أسماء أفراد العائلة الافتراضية، وتأخير وقت تهيئة إنشاء مخطط المعرفة (knowledge graph). كما اعترف فريق التطوير لاحقًا بهذه الأخطاء، ويقوم حاليًا بحل مشكلات الكود تدريجيًا بالتعاون مع المجتمع.
برمجة Vibe Coding لميلا جوفوفيتش: رائعة في طريقة التنفيذ، لكن التسويق غير رائع
بالنسبة لمشروع MemPalace، توصل مستخدمو Hacker News مثل darkhanakh إلى نتيجة مفادها: يمنح MemPalace انطباعًا شبيهًا بـ OpenClaw، أي أنه يقوم بالتحكم الاصطناعي في نتائج الاختبارات القياسية (benchmark) ليظهرها خالية من العيوب تمامًا، ثم يقوم بتغليفها كإنجاز اختراق كبير للتسويق.
يرى أن التقنية الأساسية لـ MemPalace قد تكون مثيرة للاهتمام بالفعل، لكن في ظل وجود عيوب في أسلوب الاختبار، ومع ذلك ما زال يتصدر أيضًا شعار «أعلى درجات منشورة علنًا في التاريخ» للترويج؛ فهذا غير مناسب. «لكن، مع ذلك، ما يهمني هو أنني أجد أن قيام ميلا جوفوفيتش بلعب Vibe Coding أمر ممتع جدًا.»
قراءة ممتدة:
تعليم كتابة برامج يخرج عن السيطرة! تطبيق «صائد متعلقات المتجر» ذو صلاحية يومية قصيرة يواجه مشكلات أمنية، والـ GPS في المنزل يبث بشكل كامل دون ستر
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
