加密KFA
用户暂无简介
加密KFA
第一批最值得布局的 5 个方向
第一名:QCOM
角色:端侧 AI / AI PC / AI手机 / XR / 汽车智能化。
第二名:GOOG
角色:AI平台现金流 + 搜索现金牛 + TPU / Cloud。
GOOG 是风险收益最均衡的 AI 平台资产。它没有 NVDA 那么拥挤,也不是纯硬件周期股。适合作为“AI核心底仓”。
第三名:CEG 或 GEV 二选一
角色:AI物理基础设施。
Leopold 框架强调不要只买模型或芯片,要买物理层:电力、存储、互联、算力租赁等不可绕开的上游。
CEG 更偏防守现金流,GEV 弹性更大但涨幅也大。
第四名:AVGO
角色:AI ASIC + AI网络 + 系统互连。
AVGO 是 AI第二阶段最核心的“网络/ASIC价值捕获层”。但它现在太拥挤,不能因为逻辑强就追。
第五名:MU / SNDK 二选一
角色:存储 / DRAM / HBM / SoCAMM。
存储是当期业绩最硬的瓶颈,但涨幅已经很大。动态蒸馏库里明确:存储是当前显性业绩瓶颈,光互联是下一阶段结构瓶颈,但必须区分现期 EPS 兑现和远期架构切
第一名:QCOM
角色:端侧 AI / AI PC / AI手机 / XR / 汽车智能化。
第二名:GOOG
角色:AI平台现金流 + 搜索现金牛 + TPU / Cloud。
GOOG 是风险收益最均衡的 AI 平台资产。它没有 NVDA 那么拥挤,也不是纯硬件周期股。适合作为“AI核心底仓”。
第三名:CEG 或 GEV 二选一
角色:AI物理基础设施。
Leopold 框架强调不要只买模型或芯片,要买物理层:电力、存储、互联、算力租赁等不可绕开的上游。
CEG 更偏防守现金流,GEV 弹性更大但涨幅也大。
第四名:AVGO
角色:AI ASIC + AI网络 + 系统互连。
AVGO 是 AI第二阶段最核心的“网络/ASIC价值捕获层”。但它现在太拥挤,不能因为逻辑强就追。
第五名:MU / SNDK 二选一
角色:存储 / DRAM / HBM / SoCAMM。
存储是当期业绩最硬的瓶颈,但涨幅已经很大。动态蒸馏库里明确:存储是当前显性业绩瓶颈,光互联是下一阶段结构瓶颈,但必须区分现期 EPS 兑现和远期架构切
- 赞赏
- 点赞
- 评论
- 转发
- 分享
啥时候把股票上了 @armaniferrante $BP
- 赞赏
- 点赞
- 评论
- 转发
- 分享
中国证监会等八部门联合发布《综合整治非法跨境证券期货基金经营活动实施方案》,明确严禁境外机构以任何形式在境内非法提供开户、交易、资金划转等服务,并设立 2 年集中整治期清理非法存量业务。方案还提出强化跨境监管协作与全链条治理,覆盖证券监管、外汇管理、网络治理及犯罪打击等多个领域。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
最近一直在搭建自己的数据库和AI投资系统

- 赞赏
- 点赞
- 评论
- 转发
- 分享
暴论:台海若开战,老美会不会直接冻结大陆人民的美股账户?

- 赞赏
- 点赞
- 评论
- 转发
- 分享
我这新手炒美股都100%胜率,闭着眼睛都在涨的行情,不知道这些大师再装啥。。

- 赞赏
- 点赞
- 评论
- 转发
- 分享
起初人们以为这是一次普通的反弹。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
你们啥情况呢 @tradefoxai @tradefoxintern @Prithvir12
平台多日无法交易资金无法取出,发信息已读不回,也不给出公告??
预测市场怎么全是臭鱼烂虾项目?
The platform has been unable to trade for days, and I can't withdraw my funds. Messages I sent are read but get no reply, and there's still no announcement??Why is the prediction market full of nothing but trashy, low-quality garbage projects?What's going on with you guys?@tradefoxai
平台多日无法交易资金无法取出,发信息已读不回,也不给出公告??
预测市场怎么全是臭鱼烂虾项目?
The platform has been unable to trade for days, and I can't withdraw my funds. Messages I sent are read but get no reply, and there's still no announcement??Why is the prediction market full of nothing but trashy, low-quality garbage projects?What's going on with you guys?@tradefoxai

- 赞赏
- 点赞
- 评论
- 转发
- 分享
美股简单模式玩了一个月没亏过。。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
中文💩KOL集体喊单后卖给韭菜,然后换成 $SATO 了吗?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
delta看安全概率 越低越好
theta/vega看收益性价比 越高越好
IV百分位 越高卖方租金越高
theta/vega看收益性价比 越高越好
IV百分位 越高卖方租金越高
- 赞赏
- 点赞
- 评论
- 转发
- 分享
最近一直在美股卖put ,看着存储的涨幅感觉赚钱太慢了。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
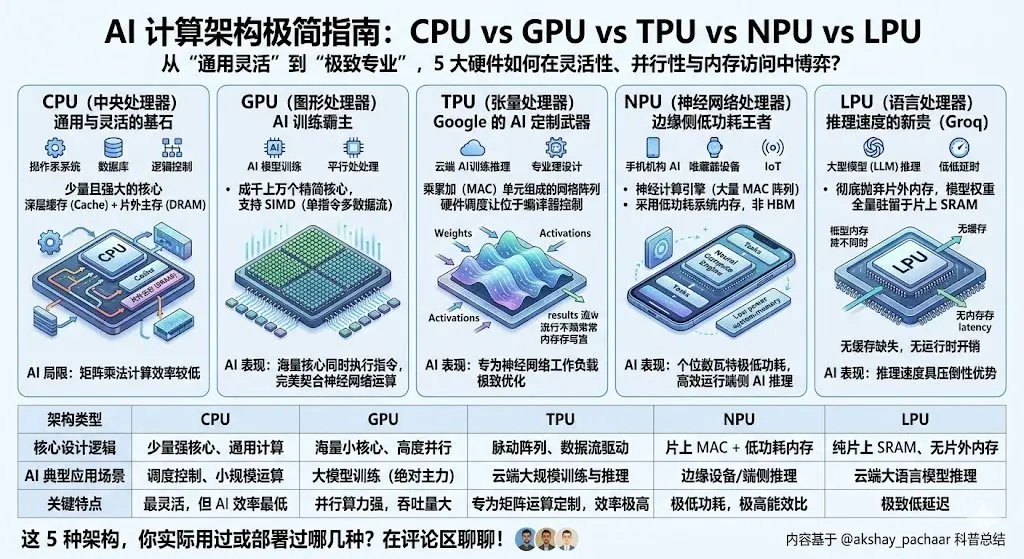
当今 AI 由 5 种硬件架构主导,每一种都在灵活性、并行性和内存访问之间做了不同的权衡。
CPU:通用计算设计,只有少量强大核心,擅长复杂逻辑、分支判断和系统级任务。它有深层缓存和片外 DRAM(主内存),适合操作系统、数据库等,但对神经网络所需的重复矩阵乘法不太高效。
GPU:不是少数强大核心,而是成千上万个较小核心同时执行相同指令(SIMD)。这种高度并行性完美匹配神经网络的数学运算,因此主导了 AI 训练。
TPU(Google 设计):进一步专业化。核心是乘累加(MAC)单元组成的网格,数据以“波浪”形式流动——权重从一边进入,激活值从另一边进入,结果直接传播,无需每次回写内存。整个执行由编译器控制(非硬件调度),专门为神经网络工作负载优化。
NPU(Neural Processing Unit):边缘设备优化版。内置 Neural Compute Engine(大量 MAC 阵列 + 片上 SRAM),但使用低功耗系统内存而非高带宽 HBM。目标是在手机、可穿戴设备、IoT 等场景下以个位数瓦特功耗运行推理(Apple Neural Engine、Intel NPU 都属于此类)。
LPU(Language Processing Unit,由 Groq 推出):最新成员。完全移除片外内存,所有权重都放在片上 SRAM 中。执行完全确定性、由编译器调度,无缓存缺失、无运行
CPU:通用计算设计,只有少量强大核心,擅长复杂逻辑、分支判断和系统级任务。它有深层缓存和片外 DRAM(主内存),适合操作系统、数据库等,但对神经网络所需的重复矩阵乘法不太高效。
GPU:不是少数强大核心,而是成千上万个较小核心同时执行相同指令(SIMD)。这种高度并行性完美匹配神经网络的数学运算,因此主导了 AI 训练。
TPU(Google 设计):进一步专业化。核心是乘累加(MAC)单元组成的网格,数据以“波浪”形式流动——权重从一边进入,激活值从另一边进入,结果直接传播,无需每次回写内存。整个执行由编译器控制(非硬件调度),专门为神经网络工作负载优化。
NPU(Neural Processing Unit):边缘设备优化版。内置 Neural Compute Engine(大量 MAC 阵列 + 片上 SRAM),但使用低功耗系统内存而非高带宽 HBM。目标是在手机、可穿戴设备、IoT 等场景下以个位数瓦特功耗运行推理(Apple Neural Engine、Intel NPU 都属于此类)。
LPU(Language Processing Unit,由 Groq 推出):最新成员。完全移除片外内存,所有权重都放在片上 SRAM 中。执行完全确定性、由编译器调度,无缓存缺失、无运行
- 赞赏
- 点赞
- 评论
- 转发
- 分享
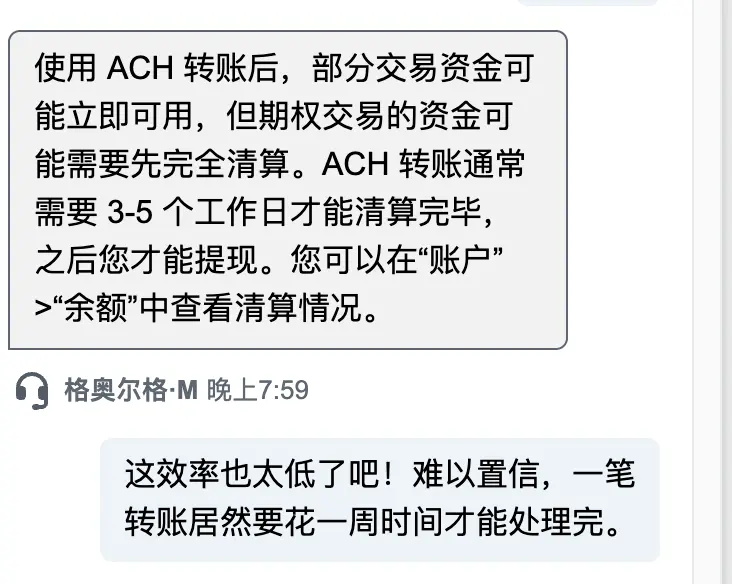
上周日从WISE转账一笔钱到嘉信理财
到现在还没入账
这对币圈原住民来说真是难以想象的低效
到现在还没入账
这对币圈原住民来说真是难以想象的低效
- 赞赏
- 点赞
- 评论
- 转发
- 分享
看了一圈,又有好多人退圈了,离开币圈他们都去哪里了?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
热门话题
查看更多302.07万 热度
28.27万 热度
107.31万 热度
1263.37万 热度
15.38万 热度
置顶
📢 Gate 广场 TradFi 交易分享挑战上线!
晒单瓜分 $30,000 奖池,新人首帖 100% 中奖!
📌 参与方式:
带 #TradFi交易分享挑战 发帖,满足以下任一即可:
🔹 带今日指定 TradFi 币种标签发帖交流。
🔹 完成单笔大于 $10U 的 TradFi CFD 交易并挂载交易卡片。
🏷️ 今日指定标签:USDJPY、AUDUSD、US30、TSLA、JPN225
🎁 宠粉福利:
1️⃣ 卡片分享奖: 抽 50 人,每人送 $100 仓位体验券!
2️⃣ 发帖榜单奖: 冲排行榜,赢 WCTC 限定 T 恤!
3️⃣ 新粉见面礼: 新人首次发帖,100% 领 $10 体验券!
详情:https://www.gate.com/announcements/article/51221✍️ Gate 广场「创作者认证激励计划」持续招募中!
广场发帖创作,即可瓜分每月 $10,000+ 奖励!
豪华代币奖池、Gate 周边、专属推广与千万级流量曝光等你拿!
广场认证创作者、其他平台优质创作者均可报名
立即填写表单报名 👉 https://www.gate.com/questionnaire/7159
让优质内容被更多人看到,一起共建创作者社区!
活动详情:https://www.gate.com/announcements/article/47889
创作者认证申请详情:https://www.gate.com/help/community-center/moments/47731/gate-square-creator-certification-guidelines