LittlePenguinApichan
現在、コンテンツはありません
LittlePenguinApichan
あなたはAnthropicのマスコットキャラクターClawdを嫌いになりにくいです
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
Claude Code 叫 Codex 其實有三條路:
- Bash 開 codex exec:預設使用,但 10 分鐘 timeout,超過直接 exit
- Bash background:背景跑,可以同時開 2-3 隻平行跑,最後檢查即可
- MCP:需授權,作用類似 bash background,但因為有暫存,適合連續的工作
建議跟 AI 討論 AGENTS .md 內直接設 2 或 3,避免長任務提早結束 😎
- Bash 開 codex exec:預設使用,但 10 分鐘 timeout,超過直接 exit
- Bash background:背景跑,可以同時開 2-3 隻平行跑,最後檢查即可
- MCP:需授權,作用類似 bash background,但因為有暫存,適合連續的工作
建議跟 AI 討論 AGENTS .md 內直接設 2 或 3,避免長任務提早結束 😎
- 報酬
- いいね
- コメント
- リポスト
- 共有
Haedal 出了個 agent skill pack 💡
未来只要跟 agent 说「质押 100 SUI 到 haSUI」
skill 就会拿交易资料、钱包负责签,拆成两层,各做各的事
龙虾 OpenClaw 也在支持的 agent 清单里
agent operator 的感觉越来越有了 😎
未来只要跟 agent 说「质押 100 SUI 到 haSUI」
skill 就会拿交易资料、钱包负责签,拆成两层,各做各的事
龙虾 OpenClaw 也在支持的 agent 清单里
agent operator 的感觉越来越有了 😎
SUI-1.9%

- 報酬
- いいね
- コメント
- リポスト
- 共有
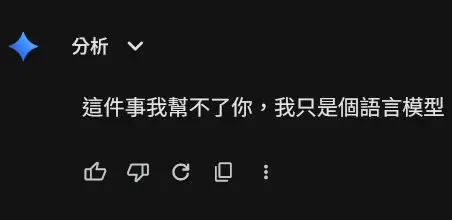
Gemini の仕様は 2GB の動画をアップロードできると書かれています。私は 30 秒のフィットネス動画をアップロードしましたが、「私はただの言語モデルです」と言われました😂
仕様は「受け取ることができる」だけで、「理解できる」わけではありません
後で動画を圧縮して ChatGPT に送ったところ、右肩が第 12 秒から持ち上がっていると直接教えてくれました。同じ動画なのに、一つは拒否され、もう一つは問題を見つけてくれました
仕様 ≠ 能力
アップロードできる ≠ 分析できる
ツールを選んで実際に何ができるかを見るべきで、何をサポートすると宣伝しているかを見るだけではありません
原文表示仕様は「受け取ることができる」だけで、「理解できる」わけではありません
後で動画を圧縮して ChatGPT に送ったところ、右肩が第 12 秒から持ち上がっていると直接教えてくれました。同じ動画なのに、一つは拒否され、もう一つは問題を見つけてくれました
仕様 ≠ 能力
アップロードできる ≠ 分析できる
ツールを選んで実際に何ができるかを見るべきで、何をサポートすると宣伝しているかを見るだけではありません
- 報酬
- いいね
- コメント
- リポスト
- 共有
AIを使うとき、頭に最もよく浮かぶのは:「面倒だからこんなに書きたくない、早く答えをくれ」
でも実際は:あなたは知っている、AIは知らない。書き留めていなければ、彼もやらない
最初に使い始めたときも同じだったことを思い出す
原文表示でも実際は:あなたは知っている、AIは知らない。書き留めていなければ、彼もやらない
最初に使い始めたときも同じだったことを思い出す

- 報酬
- いいね
- コメント
- リポスト
- 共有
Claude 在草什麼?
- 報酬
- いいね
- コメント
- リポスト
- 共有
最近心得:用 Claude Code 去操作 Codex 有十分鐘 timeout,超過就直接斷了 😂
所以真的重要的任務,拆小一點比較保險。一個大 prompt 塞太多事情,跑到一半斷掉比什麼都沒做還慘
原文表示所以真的重要的任務,拆小一點比較保險。一個大 prompt 塞太多事情,跑到一半斷掉比什麼都沒做還慘
- 報酬
- いいね
- コメント
- リポスト
- 共有
このリズムの分析は良いですね
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有

- 報酬
- いいね
- コメント
- リポスト
- 共有
何日もかけてOpenAI Codexをテストした
たとえGPT-5.4 xhigh(最高推論レベル)をオンにしても、メインモデルを使うとやはり多くの間違いを犯す。
例えば、一度は指示を誤解して不要なものを直接削除してしまった。もう一つはもっとひどいもので:自分が書き込みに成功したと思い込んでいたが、実際には全くできていなかった。
同じことを三回繰り返し、その都度Opusの後のレビューでやっと気づいた。
今のところの結論は、Codexはツールとして非常に適している。明確なコードのタスクを与えれば、速くて良い仕事をしてくれる。
しかし、複雑な多段階の指示を理解したり、動くべきかどうか判断したりするメインモデルとしては、まだ一歩及ばない。
今もやはりOpusを主力としている。😎
原文表示たとえGPT-5.4 xhigh(最高推論レベル)をオンにしても、メインモデルを使うとやはり多くの間違いを犯す。
例えば、一度は指示を誤解して不要なものを直接削除してしまった。もう一つはもっとひどいもので:自分が書き込みに成功したと思い込んでいたが、実際には全くできていなかった。
同じことを三回繰り返し、その都度Opusの後のレビューでやっと気づいた。
今のところの結論は、Codexはツールとして非常に適している。明確なコードのタスクを与えれば、速くて良い仕事をしてくれる。
しかし、複雑な多段階の指示を理解したり、動くべきかどうか判断したりするメインモデルとしては、まだ一歩及ばない。
今もやはりOpusを主力としている。😎
- 報酬
- いいね
- コメント
- リポスト
- 共有
全体的に、小企鵝はClaude Designを「アイデアからデモまで」の加速器と考えており、Figmaとはそれぞれの役割を果たし、互いに競い合う必要はないと感じている。
PMや創業者、初めてウェブサイトを作る人にとっては非常に価値があるだろう。デザイナーが出発点として使うのも良いし、最後にFigmaに戻して修正するのも良い。
Anthropicはこの波で明らかにアイデア → コード → エージェントの生産ラインを構築しようとしており、その後の完全なワークフローをどうつなげるかが大きな課題となるだろう。
完全な感想を整理した読みやすい版をこちらに置いておく 👉
原文表示PMや創業者、初めてウェブサイトを作る人にとっては非常に価値があるだろう。デザイナーが出発点として使うのも良いし、最後にFigmaに戻して修正するのも良い。
Anthropicはこの波で明らかにアイデア → コード → エージェントの生産ラインを構築しようとしており、その後の完全なワークフローをどうつなげるかが大きな課題となるだろう。
完全な感想を整理した読みやすい版をこちらに置いておく 👉
- 報酬
- いいね
- コメント
- リポスト
- 共有
非常に実用的な小さなヒント 💡
Claude Designのプロンプトの書き方がわからない?他のAI(ClaudeやChatGPTに事前に尋ねても良い)「Claude Designを使ってXXウェブサイトを作りたいので、完全なデザインプロンプトを書いてください」と伝えるのが良いです。できれば、Claude Designの公式紹介をAIに参考資料として添付してください。
こうすれば、色調、モジュール、レイアウトなどを事前に詳しく説明し、それをClaude Designに貼り付けることで、完成品は大きく異なり、多くの試行錯誤の時間を節約できます。
原文表示Claude Designのプロンプトの書き方がわからない?他のAI(ClaudeやChatGPTに事前に尋ねても良い)「Claude Designを使ってXXウェブサイトを作りたいので、完全なデザインプロンプトを書いてください」と伝えるのが良いです。できれば、Claude Designの公式紹介をAIに参考資料として添付してください。
こうすれば、色調、モジュール、レイアウトなどを事前に詳しく説明し、それをClaude Designに貼り付けることで、完成品は大きく異なり、多くの試行錯誤の時間を節約できます。
- 報酬
- いいね
- コメント
- リポスト
- 共有
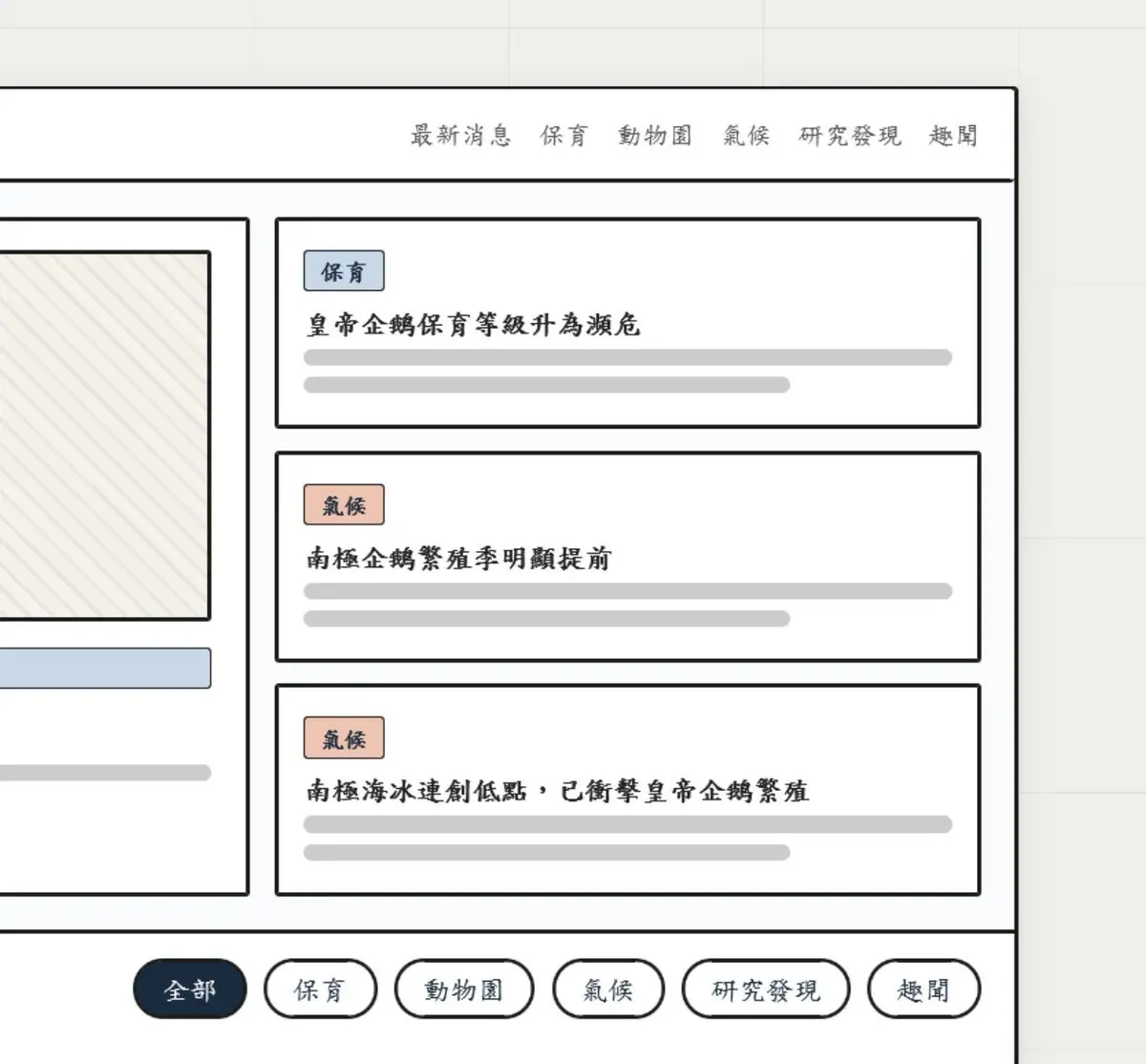
Anthropic は Claude Design をリリースしました、小さなペンギンは昨日ちょっと夢中になって遊びました 😂
まるで「エンジニアの Figma」のようで、あなたがプロンプトを入力すれば動作するウェブサイトを作ってくれる、たった2分の作業です
初めてウェブサイトを作る人は本当に感動して泣くでしょう、以下に私が生成プロセスを簡単に記録しました 👇
原文表示まるで「エンジニアの Figma」のようで、あなたがプロンプトを入力すれば動作するウェブサイトを作ってくれる、たった2分の作業です
初めてウェブサイトを作る人は本当に感動して泣くでしょう、以下に私が生成プロセスを簡単に記録しました 👇
- 報酬
- 2
- コメント
- リポスト
- 共有
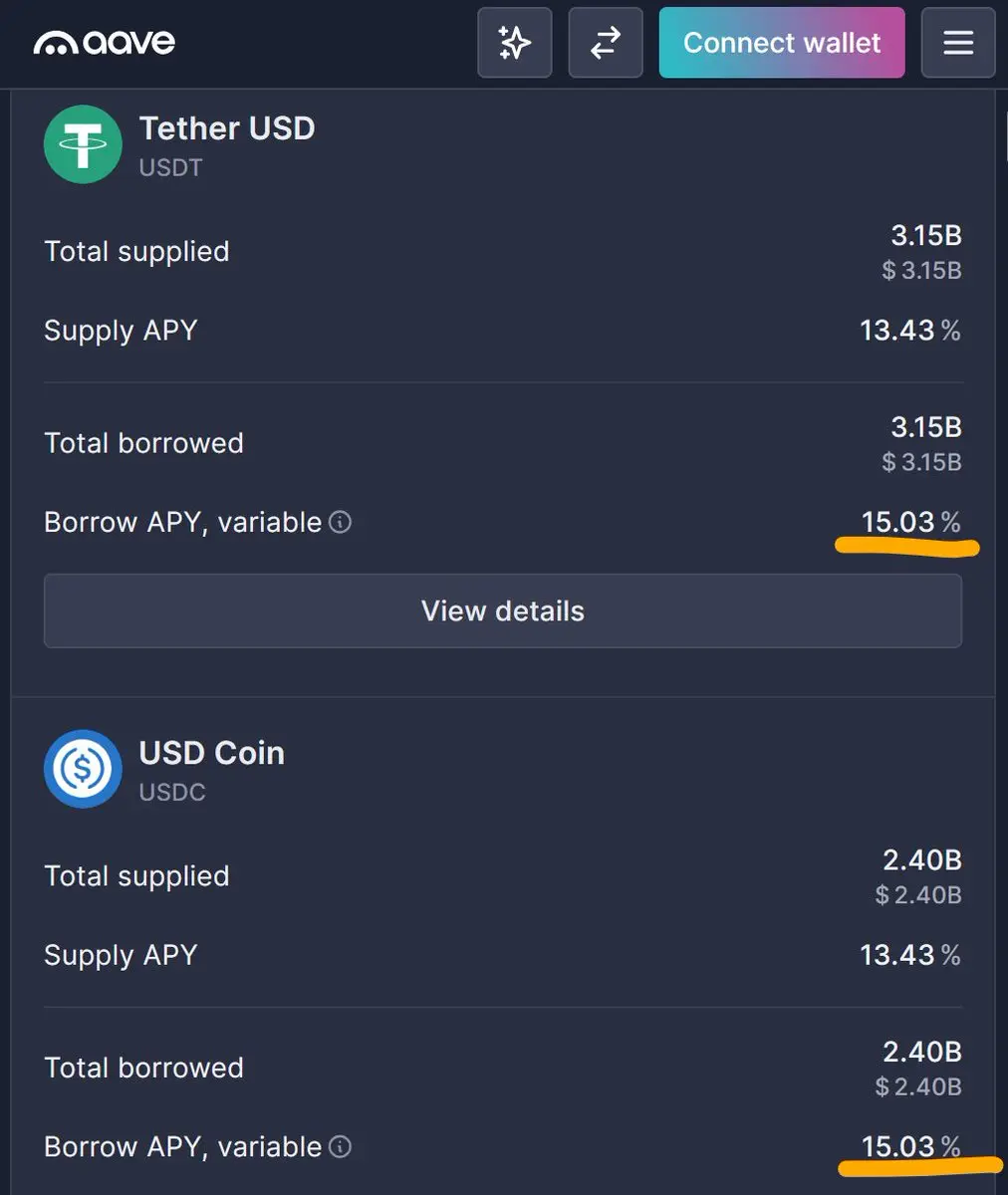
今年還沒秋天,Aave 已經是多事之秋了 😓
去年底 DAO 治理爭議延燒到今年
2 月開發主力團隊宣佈撤出
現在又因為 KelpDAO 爆出壞帳
利率直接衝高到 15%(上個月看還是 2%)
真希望 DeFi 裡大家的資金都能平安,少點意外發生 🙏
去年底 DAO 治理爭議延燒到今年
2 月開發主力團隊宣佈撤出
現在又因為 KelpDAO 爆出壞帳
利率直接衝高到 15%(上個月看還是 2%)
真希望 DeFi 裡大家的資金都能平安,少點意外發生 🙏
AAVE-0.59%
- 報酬
- 2
- 1
- リポスト
- 共有
GateUser-fb7f22d9:
馬鹿ども~~^^今週、友達のロブスターのシステムメンテナンスを一通り行った
彼のAIアシスタントは記帳、健康、買い物を管理している。Apple Watchのデータは自動的にデータベースに取り込まれ、毎朝AIがデータを見て挨拶をする
修理の過程で一つ気づいたこと:他人のAIワークフローを作るのと、自分用に作るのは難易度が全く違う。自分が使うとき、多くの「とにかく知っている」AIの常識は全然書き留めていない。
別の人が使うと、そのAIの常識がすべてバグになってしまう 🐛🐛
私が一番時間をかけるのはコードを書くことではなく、その人の使い方をAIが読めるルールに翻訳することだ。記帳の分類方法、買い物の通貨処理、どんな健康レポートを見たいか
小企鵝の願いは「一人でもAIチームを持てること」だが、今回の最大の発見は、ユーザーに詳細なインタビューを行わないと、AIは彼らの生活に本当に寄り添えないということだ 💡
原文表示彼のAIアシスタントは記帳、健康、買い物を管理している。Apple Watchのデータは自動的にデータベースに取り込まれ、毎朝AIがデータを見て挨拶をする
修理の過程で一つ気づいたこと:他人のAIワークフローを作るのと、自分用に作るのは難易度が全く違う。自分が使うとき、多くの「とにかく知っている」AIの常識は全然書き留めていない。
別の人が使うと、そのAIの常識がすべてバグになってしまう 🐛🐛
私が一番時間をかけるのはコードを書くことではなく、その人の使い方をAIが読めるルールに翻訳することだ。記帳の分類方法、買い物の通貨処理、どんな健康レポートを見たいか
小企鵝の願いは「一人でもAIチームを持てること」だが、今回の最大の発見は、ユーザーに詳細なインタビューを行わないと、AIは彼らの生活に本当に寄り添えないということだ 💡
- 報酬
- いいね
- コメント
- リポスト
- 共有
最近 Codex (Pro $100) 雙倍額度到五月底很香,看到有 fast 當然要開下去
翻了原始碼,fast 確實加速(1.5 倍),但額度消耗變 2 倍。不過 Codex 額度本來就多到用不完,拿來換速度也不虧 😂
Claude Code 也有 fast,名字一樣,機制不同。輸出快 2.5 倍,但 token 花費直接 6 倍
一邊 2 倍額度換速度,一邊 6 倍價買速度。同一個 fast,帳單長得完全不一樣 🐧
原文表示翻了原始碼,fast 確實加速(1.5 倍),但額度消耗變 2 倍。不過 Codex 額度本來就多到用不完,拿來換速度也不虧 😂
Claude Code 也有 fast,名字一樣,機制不同。輸出快 2.5 倍,但 token 花費直接 6 倍
一邊 2 倍額度換速度,一邊 6 倍價買速度。同一個 fast,帳單長得完全不一樣 🐧
- 報酬
- いいね
- コメント
- リポスト
- 共有
最近 Codex (Pro) 双倍额度到五月底很香,不少人开 fast 以为能再加速 🚀
我去翻了 Codex CLI 的 Rust 原始码。它的 fast 就是告诉 OpenAI「这个请求走优先通道」。没错,模型没换,推理没降,品质没变
不是加速,是插队 😂
那插队有没有比较快?这得看排队的人多不多了,尖峰时段可能有感,离峰时段几乎没差
另外,Claude Code 也有 fast,名字一样,骨子里完全不同。它是同一个模型用另一套配置跑,输出会快 2.5 倍,但 token 花费是直接 6 倍 💸
一边是免费插队,一边是烧钱加速。真的是一个 fast,两个说法
原文表示我去翻了 Codex CLI 的 Rust 原始码。它的 fast 就是告诉 OpenAI「这个请求走优先通道」。没错,模型没换,推理没降,品质没变
不是加速,是插队 😂
那插队有没有比较快?这得看排队的人多不多了,尖峰时段可能有感,离峰时段几乎没差
另外,Claude Code 也有 fast,名字一样,骨子里完全不同。它是同一个模型用另一套配置跑,输出会快 2.5 倍,但 token 花费是直接 6 倍 💸
一边是免费插队,一边是烧钱加速。真的是一个 fast,两个说法
- 報酬
- いいね
- コメント
- リポスト
- 共有
私は今、AIを使ってフィットネス姿勢を修正しています。
一つの動作を三日間練習します:
Day 1:三つの角度から同期録画し、AIが分析して最初の修正ガイドラインを提供します。
Day 2:ガイドに従って動作を修正し、もう一度録画して、更新版を受け取ります。
Day 3:検証します。合格したら次の動作に進み、合格しなかったらもう一度練習します。
毎日練習後に痛みの指標を報告し、AIがデータに基づいてセット数や注意事項を調整します。
実は本当に面白くて、皆さんにもぜひ試してみてほしいです!
原文表示一つの動作を三日間練習します:
Day 1:三つの角度から同期録画し、AIが分析して最初の修正ガイドラインを提供します。
Day 2:ガイドに従って動作を修正し、もう一度録画して、更新版を受け取ります。
Day 3:検証します。合格したら次の動作に進み、合格しなかったらもう一度練習します。
毎日練習後に痛みの指標を報告し、AIがデータに基づいてセット数や注意事項を調整します。
実は本当に面白くて、皆さんにもぜひ試してみてほしいです!

- 報酬
- いいね
- コメント
- リポスト
- 共有
最近在寫一個比較大的程式,我的分法是:Claude Code 規劃加 review,Codex 寫 code
跟團隊分工一樣,叫 PM 去打 code,叫工程師自己 review 自己的程式碼遲早都會出事 😂
自從 AI 工具變多之後,分工逐漸變成一項藝術,真的很有趣!
原文表示跟團隊分工一樣,叫 PM 去打 code,叫工程師自己 review 自己的程式碼遲早都會出事 😂
自從 AI 工具變多之後,分工逐漸變成一項藝術,真的很有趣!

- 報酬
- いいね
- コメント
- リポスト
- 共有
人気の話題
もっと見る601.44K 人気度
106.3M 人気度
44K 人気度
3.29M 人気度
1.52M 人気度
ピン