在实际使用中,开发者或用户提交 AI 请求后,并不会直接得到一个不可验证的结果,而是进入一个包含计算、验证与记录的多阶段流程。这种流程设计源于对“结果可信性”的需求,尤其是在自动化决策与数据处理等场景中尤为关键。
这一执行过程通常涉及请求入口、推理执行、结果验证与链上确认等多个层面,这些模块之间的协同构成了 OpenGradient 的运行逻辑。
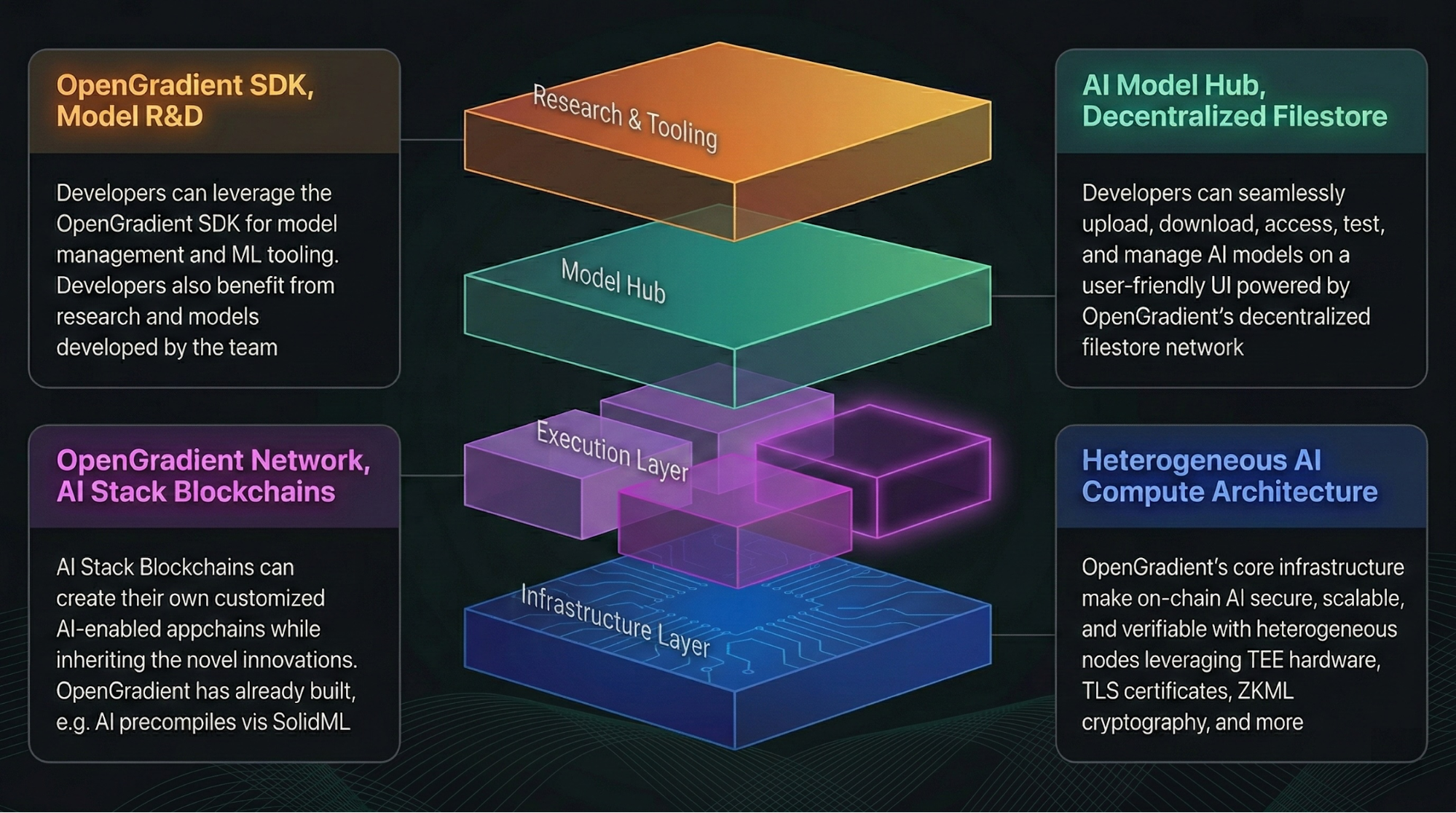
用户如何接入 OpenGradient 网络
用户接入是整个流程的起点。
在机制上,开发者通过 API 或 SDK 将应用连接至 OpenGradient 网络,并提交包含模型参数与输入数据的推理请求。系统接收请求后,会对其进行格式化处理与任务分配准备。
从结构上看,接入层位于网络最外层,负责将用户请求转化为内部可执行任务,并将其发送至调度系统。这一层通常包含接口服务与请求管理模块。
这一设计的意义在于,将复杂的分布式计算隐藏在统一接口之后,使用户无需理解底层结构即可使用网络。
AI 请求在 OpenGradient 中如何被提交
请求提交阶段决定任务如何进入执行流程。
在机制上,系统在接收到请求后,会根据任务类型、计算复杂度与节点状态,将任务分配给合适的推理节点。这一过程通常通过调度算法完成,以优化资源使用效率。
从结构上看,请求管理模块会记录任务信息,并生成唯一标识,用于后续跟踪与验证。任务随后进入执行队列,等待推理节点处理。
这一机制的意义在于,通过统一调度实现资源分配,使计算能力能够高效利用,同时避免节点拥堵。
推理节点如何执行模型计算
推理节点承担实际计算任务。
在机制上,节点接收到任务后,在本地运行 AI 模型,对输入数据进行处理并生成输出结果。同时,为保证结果可验证,节点还会生成相关证明数据。
从结构上看,推理节点包含模型执行环境与结果生成模块,通常运行在受控环境中,以确保计算过程稳定且可重复。
这一阶段的意义在于,将计算与验证准备同步完成,为后续验证提供基础。
验证节点如何校验推理结果
验证节点负责确认结果的可信性。
在机制上,验证节点会接收推理节点输出的结果与证明数据,通过独立计算或验证算法确认结果是否正确。如果验证失败,结果将被拒绝或重新计算。
从结构上看,验证层独立于执行层存在,使验证过程不依赖原始计算节点,从而提高系统安全性。
这一机制的意义在于,将信任从单一节点转移到整个网络,使系统具备抗篡改能力。
链上记录如何完成最终确认
链上记录用于固定最终结果。
在机制上,通过验证的结果会被提交至区块链或相关数据层进行记录,形成不可篡改的执行证明。这一过程通常包括数据打包与确认步骤。
从结构上看,链上层位于流程末端,负责将结果写入分布式账本,确保其长期可追溯。
这一设计的意义在于,使计算结果具备持久性与审计能力,为后续查询与验证提供依据。
模块之间如何协同完成执行
多个模块的协同决定整体效率。
在机制上,请求层、执行层、验证层与记录层通过消息传递与任务调度进行连接,每一阶段完成后将结果传递至下一阶段。
从结构上看,各模块之间形成流水线式结构,使任务能够连续处理而非阻塞执行。
| 模块 | 功能 | 位置 |
|---|---|---|
| 接入层 | 接收请求 | 起点 |
| 调度层 | 分配任务 | 中间 |
| 推理节点 | 执行计算 | 核心 |
| 验证节点 | 校验结果 | 安全层 |
| 链上层 | 记录结果 | 终点 |
这种协同方式的意义在于,提高整体吞吐能力,同时确保每一步都有明确职责。
OpenGradient 推理流程的结构拆解
整体流程可以拆解为连续步骤。
在机制上,一个完整任务通常经历:请求提交 → 任务分配 → 模型执行 → 结果生成 → 验证确认 → 链上记录。这些步骤构成闭环。
从结构上看,各步骤由不同模块负责,使系统具备清晰的责任划分与扩展能力。
这一流程的意义在于,将复杂的计算过程拆分为标准化步骤,从而提升系统可维护性与可扩展性。
总结
OpenGradient 通过将 AI 推理、结果验证与链上记录拆分为多个协同模块,构建了一个可验证的计算流程,使去中心化 AI 网络能够在效率与可信性之间实现平衡。
FAQ
OpenGradient 是如何处理 AI 请求的? 用户提交请求后,系统将任务分配给推理节点执行,并进入验证流程。
为什么需要验证节点? 用于独立校验推理结果,避免对单一节点的信任依赖。
链上记录在流程中有什么作用? 用于保存最终结果,使其具备不可篡改与可审计特性。
推理节点和验证节点有什么区别? 推理节点负责计算结果,验证节点负责确认结果是否正确。
OpenGradient 的流程为什么要分阶段执行? 分阶段可以提高效率并增强安全性,使每个模块专注于特定任务。
分享
目录


相关文章

不可不知的比特币减半及其重要性

如何选择比特币钱包?


CKB:闪电网络促新局,落地场景需发力

Master Protocol:激活 BTC 生息潜力
