ロボティクスAIとエンボディードAIの台頭に伴い、現実世界の行動データへの需要が急増しており、分散型データネットワークがAIインフラの重要な柱として浮上しています。
Caspiusと従来のAIデータプラットフォームは、いずれもAIトレーニングデータの収集を目的としており、比較対象となることが少なくありません。両者ともAIモデルのトレーニングを支援しますが、データ管理、価値分配ロジック、エコシステムの構造において根本的に異なります。
Caspiusとは
Caspiusは、ロボティクスAIとエンボディードAIに特化したデータインフラプロトコルです。現実世界の行動データをオープンネットワークで収集し、AIモデルトレーニングの原材料を提供します。
このプロジェクトは、ロボットのトレーニングに不可欠な一人称視点の動画、動作軌跡、環境インタラクションデータに焦点を当てています。これらのデータにより、ロボットは現実世界での動作実行、空間推論、物理的フィードバックを習得できます。
従来のプラットフォームとは異なり、Caspiusはブロックチェーン上のインセンティブメカニズムを活用し、一般ユーザーがデータを提供できる仕組みを採用しています。有効なトレーニングデータをアップロードすると、ユーザーはCASトークンで報酬を受け取れます。
ポジショニングの観点では、CaspiusはオープンなAIデータネットワークやDePINインフラプロジェクトに近い位置づけです。
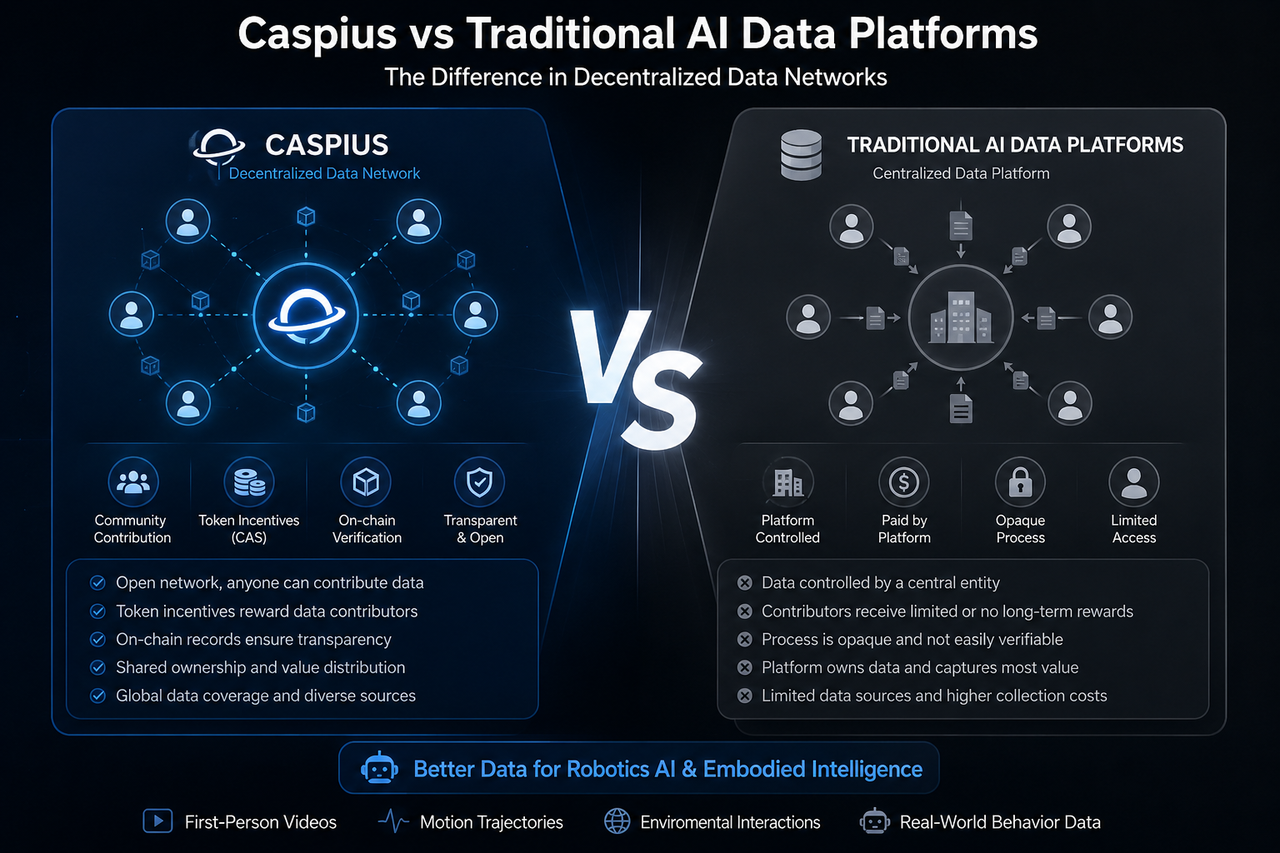
従来のAIデータプラットフォームとは
従来のAIデータプラットフォームは、通常、中央集権的な企業が運営し、データ収集、アノテーション、整理、販売を一貫して行います。
従来のモデルでは、プラットフォームがデータ収集のワークフローを標準化します。その後、アノテーションチームがデータを分類・処理し、最終的にAI企業にトレーニングデータサービスを提供します。現在、多くの大規模言語モデル、画像認識システム、自動運転モデルが、これらのプラットフォームのデータに依存しています。
この方法は、長年にわたりAI業界の標準となっており、運用効率と成熟したデータ検証プロセスが評価されています。ただし、データと収益分配の管理は、プラットフォーム内に集中する傾向があります。
Caspiusと従来のAIデータプラットフォームでは、データ所有権はどのように異なるのか
データ所有権は、Caspiusと従来のAIデータプラットフォームの重要な違いの1つです。
従来のプラットフォームは、一般的に中央集権型モデルを採用しています。データを収集、保存、収益化し、提供者は継続的な価値分配にほとんど関与しません。
一方、Caspiusはオープンなコラボレーションとオンチェーンインセンティブロジックを重視します。理論上、データ提供者はトレーニングデータをアップロードするだけでなく、トークンメカニズムを通じてエコシステムの価値フローに参加できます。
次の表に、データに関する構造的な違いを示します。
| 比較項目 | Caspius | 従来のAIデータプラットフォーム |
|---|---|---|
| データ管理方法 | オープンネットワーク | 中央集権的プラットフォーム管理 |
| データ提供モデル | コミュニティ連携 | 企業による収集 |
| 収益分配 | オンチェーンインセンティブメカニズム | プラットフォーム主導 |
| データ透明性 | 検証可能な仕組み | 不透明なプロセス |
| ネットワーク構造 | 分散型 | 中央集権型 |
これらの違いにより、CaspiusはWeb3データエコノミーに近い位置づけといえます。
Caspiusと従来のAIデータプラットフォームでは、インセンティブメカニズムはどのように異なるのか
従来のAIデータプラットフォームは、通常、固定報酬モデルで運営されます。たとえば、データ収集者やアノテーションチームに支払いを行い、処理済みデータをAI企業に販売します。
一方、Caspiusはトークンインセンティブを活用してデータ供給を拡大します。有効なトレーニングデータをアップロードしたユーザーはCASトークンを受け取り、ネットワークは経済的報酬を通じてより多くの提供者を引き付けます。
このモデルの最大の利点は、誰でも参加できる点にあります。企業管理のデータ収集に依存する従来のプラットフォームとは異なり、Caspiusはコミュニティ連携とグローバルなデータ調達を重視します。
ただし、トークンインセンティブモデルは、市場サイクル、トークン価格の変動、エコシステムの発展ペースの影響を受ける可能性があり、長期的な実行可能性はまだ不透明です。
Caspiusと従来のAIデータプラットフォームでは、データの透明性と検証可能性はどのように異なるのか
従来のAIデータプラットフォームは、通常、クローズドシステムとして運営され、外部の者がデータの出所、フィルタリング基準、監査基準を追跡することは困難です。
Caspiusは、オンチェーンの仕組みを通じて透明性を高めることを目指しています。たとえば、特定のデータプロセスにはオンチェーン記録、検証可能な提供、コミュニティ監査が含まれ、オープンな連携を強化します。
AIデータネットワークでは、透明性の重要性が増しています。AIモデルが大規模化するにつれ、市場はトレーニングデータの出所と品質管理に注目しています。
ただし、ロボットトレーニングデータの場合、オンチェーン記録だけでは品質を保証するには不十分であり、堅牢なデータ検証メカニズムが不可欠です。
Caspiusはどのような課題に直面しているのか
分散型AIデータネットワークの成長可能性はありますが、Caspiusはいくつかのハードルを克服する必要があります。
まず、データの真正性です。ロボットトレーニングデータには高精度が求められ、低品質または偽のデータはモデルトレーニングを妨げるため、堅牢な検証が重要です。
次に、プライバシーと規制上の懸念です。現実世界の動画や行動データには、ユーザープライバシー、地理的位置情報、地域ごとに異なる規制が関与する可能性があります。
さらに、大規模なAI企業はすでに強力な自社データ収集能力を持っています。オープンデータネットワークが長期的に競争優位性を維持できるかは、まだ検証されていません。
暗号資産であるCASの市場パフォーマンスも、業界サイクルと市場変動の影響を受けます。
まとめ
Caspiusと従来のAIデータプラットフォームは、どちらもAIモデルトレーニングをサポートしますが、データネットワークの構造、価値分配ロジック、エコシステム設計において大きく異なります。
従来のプラットフォームは中央集権管理に依存するのに対し、Caspiusはオープンな連携、コミュニティ貢献、オンチェーンインセンティブを推進します。ロボティクスAIとエンボディードAIの急速な成長に伴い、現実世界のトレーニングデータへの需要は高まっており、分散型データネットワークはAIインフラの重要な要素になりつつあります。
それでも、AIデータ市場は依然として急速に進化しています。データ品質、規制遵守、エコシステムの持続可能性に関する問題は、今後も業界の長期的な方向性を形作っていくでしょう。
よくある質問
従来のAIデータプラットフォームとは何ですか
従来のAIデータプラットフォームは、通常、中央集権的な企業が運営し、データ収集、アノテーション、管理、商業販売を担当します。
Caspiusと従来のAIデータプラットフォームの最大の違いは何ですか
主な違いはデータネットワークの構造にあります。Caspiusはオープンな連携とオンチェーンインセンティブを重視するのに対し、従来のプラットフォームは中央集権管理に依存します。
ロボティクスAIにこれほど多くの現実世界のデータが必要な理由は何ですか
ロボットは、動作の実行、空間関係、環境とのインタラクションを学習する必要があります。テキストデータだけでは、複雑な行動のトレーニングには不十分です。
分散型AIデータネットワークのリスクは何ですか
分散型データネットワークは、データの真正性、プライバシーコンプライアンス、データ品質、エコシステムの持続可能性に関する課題に直面する可能性があります。
共有
内容


関連記事

Render、io.net、Akash:DePINハッシュレートネットワークの比較分析

AI分野におけるRenderの申請理由:分散型ハッシュレートが人工知能の発展を支える仕組み

SentioとThe Graph:リアルタイムインデックス機構とサブグラフインデックス機構の比較

USD.AI 収益源分析:AIインフラ借入資金による収益創出の仕組み

STトークンのユースケースとは?Sentioエコシステムにおけるインセンティブメカニズムを詳しく解説
